
本文详细介绍一下B+树的相关原理及实现。
1. B+树
B+树是一种数据结构,是一个N叉排序树,每个节点通常有多个孩子,一棵B+树包含根节点、内部节点和叶子节点。根节点可能是一个叶子节点, 也可能是一个包含两个或两个以上孩子节点的节点。
B+树通常用于数据库和操作系统的文件系统中。NTFS、ReiserFS、NSS、XFS、JFS、ReFS和BFS等文件系统都在使用B+树作为元数据索引。B+树的特点是能够保持数据稳定有序, 其插入与修改拥有较稳定的对数时间复杂度。B+树元素自底向上插入。
1.1 B+树的定义
B+树是应文件系统所需而出的一种B-树的变型树。一棵m阶的B+树和m阶的B-树的差异在于:
1) 有n棵子树的节点中含有n个关键字(即每个关键字对应一棵子树);
2) 所有叶子节点中包含了全部关键字的信息, 及指向含这些关键字记录的指针,且叶子节点本身依关键字的大小自小而大顺序链接;
3) 所有的非终端节点可以看成是索引部分,节点中仅含有其子树(根节点)中的最大(或最小)关键字
4) 除根节点外,其他所有节点中所含关键字的个数必须>=⌈m/2⌉(注意: B-树是除根以外的所有非终端节点至少有⌈m/2⌉棵子树)
下图是所示为一棵3阶的B+树,通常在B+树上有两个指针头, 一个指向根节点,另一个指向关键字最小的叶子节点。因此,可以对B+树进行两种查找运算: 一种是从最小关键字起顺序查找,另一种是从根节点开始,进行随机查找。

下图是另一棵3阶B+树:
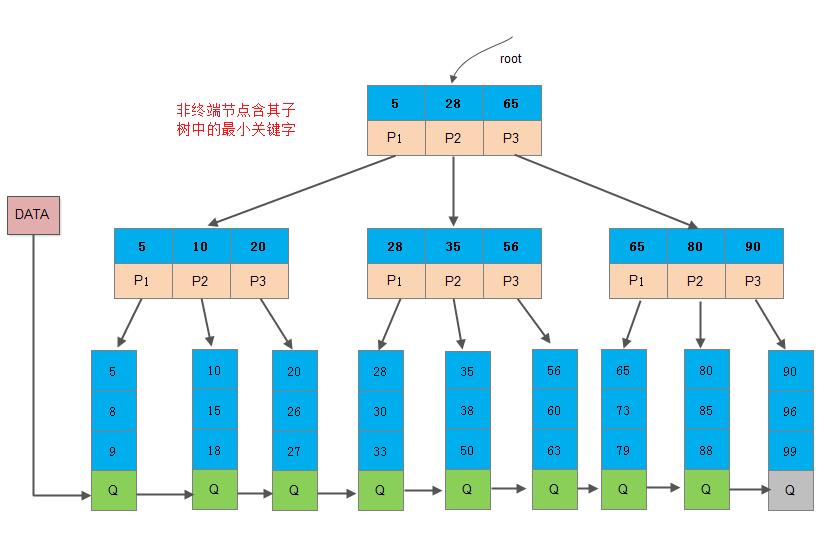
1.2 B+树的另一种定义
各种资料上B+树的定义各有不同,一种定义方式是关键字个数和孩子结点个数相同。这里我们采取维基百科上所定义的方式,即关键字个数比孩子结点个数小1,这种方式是和B树基本等价的。下图就是一颗阶数为4的B+树。
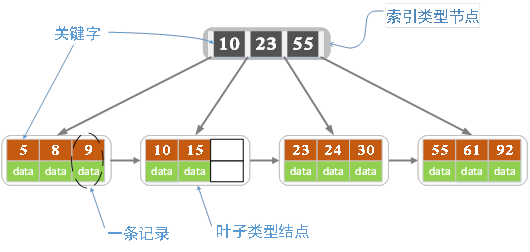
除此之外B+树还有以下的要求:
-
B+树包含2种类型的结点:内部结点(也称索引结点)和叶子结点。根结点本身即可以是内部结点,也可以是叶子结点。根结点的关键字个数最少可以只有1个。
-
B+树与B树最大的不同是内部结点不保存数据,只用于索引,所有数据(或者说记录)都保存在叶子结点中。
-
m阶B+树表示了内部结点最多有m-1个关键字(或者说内部结点最多有m个子树),阶数m同时限制了叶子结点最多存储m-1个记录。
-
内部结点中的key都按照从小到大的顺序排列,对于内部结点中的一个key,左树中的所有key都小于它,右子树中的key都大于等于它。叶子结点中的记录也按照key的大小排列。
-
每个叶子结点都存有相邻叶子结点的指针,叶子结点本身依关键字的大小自小而大顺序链接。
1.3 B+树的特性
-
所有关键字都出现在叶子节点的链表中(稠密索引),且链表中的关键字恰好是有序的;
-
不可能在非叶子节点命中;
-
非叶子节点相当于叶子节点的索引(稀疏索引),叶子节点相当于是存储(关键字)数据的数据层;
-
更适合文件索引系统;
2. B+树的查找
对B+树可以进行两种查找运算:
1) 从最小关键字起顺序查找;
2) 从根节点开始,进行随机查找
在查找时,若非终端节点上的关键字等于给定值,并不终止,而是继续向下直到叶子节点。因此,在B+树中,不管查找成功与否,每次查找都是走了一条从根到叶子节点的路径。其余同B-树的查找类似。
3. B+树的插入
m阶B+树的插入操作在叶子节点上进行,假设要插入关键字a,找到叶子节点后插入a,做如下算法判别:
1) 如果当前节点是根节点,并且插入后节点关键字数目小于等于m,则算法结束;
2) 如果当前节点是非根节点, 并且插入后节点关键字数目小于等于m,则判断若a是新索引值时转步骤4)后结束,若a不是新索引值,则直接结束;
3) 如果插入后关键字数目大于m,则先分裂成两个节点X和Y,并且他们各自所含的关键字个数分别为: u=⌈(m+1)/2⌉, v=⌊(m+1)/2⌋。由于索引值位于节点的最左端或最右端,不妨假设索引值位于节点的最右端(即非终端节点含有其子树中的最大关键字), 有如下操作:
-
如果当前分裂成的
X节点和Y节点原来所属的节点是根节点,则从X节点和Y节点中取出索引关键字,将这两个关键字组成新的根节点,并且这个根节点指向X和Y,算法结束; -
如果当前分裂成的
X节点和Y节点原来所属的节点是非根节点,依据假设条件判断,如果a成为Y节点的新索引值,则转步骤4)得到Y双亲节点P;如果a不是Y节点的新索引值,则求出X节点和Y节点的双亲节点P, 然后提取X节点的新索引值a',在P中插入关键字a',继续进行插入算法;
4) 提取节点原来的索引值b,自顶向下先判断根是否含有b,如果含有则需要先将b替换为a。然后从根节点开始,记录节点地址P, 判断P的孩子是否含有索引值b而不含索引值a,如果是则将孩子节点中的b替换为a,然后将P的孩子的地址赋值给P,继续搜索,直到发现P的孩子中已经有a值时,停止搜索,返回地址P。
3.1 B+树插入示例
下面我们给出3阶B+树插入的各种情况示例:
1) 直接插入根节点中
如下图所示,当前节点是根节点,且插入关键字90后,关键字数目小于等于3:

此时,直接插入即可。
2) 当前分裂成的X节点与Y节点原所属节点是根节点
如下图所示,当前插入节点是根节点,且插入关键字5后,该节点的关键字数目大于3,因此需要分裂成X节点和Y节点, 并将分裂出的两个节点的各自最大关键字组成新的节点,成为新的根节点: 
3) 当前节点是非根节点,且插入后节点关键字数目小于等于3
如下图所示,当前插入节点是非根节点,且插入后关键字数目小于等于3。这里可以分为两种子情况:
-
新插入的关键字是新索引值(见c图)
-
新插入的关键字
不是新索引值(见d图)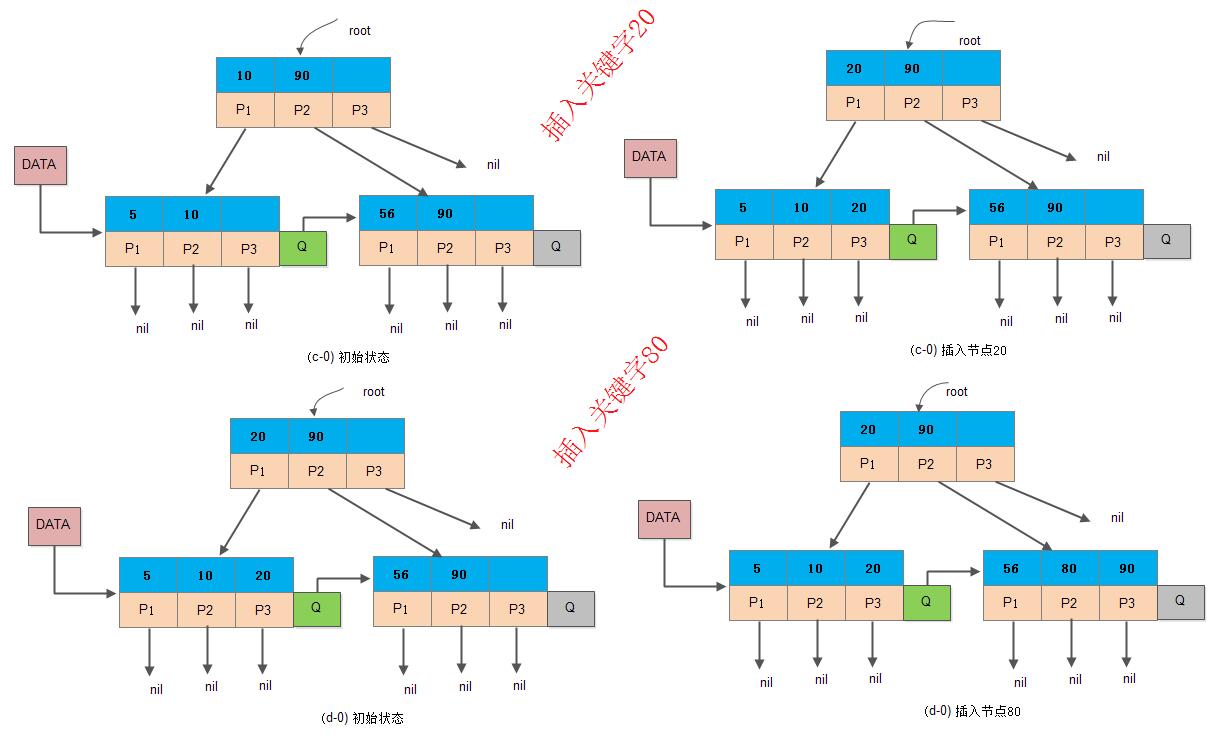
ds-bplus-tree-insert3
4) 当前节点是非根节点,且插入后节点关键字数目大于3
如下图所示,当前插入节点是非根节点,且插入关键字35后关键字数目大于3, 需要进行分裂。分裂后新插入关键字35不是Y节点的新索引值,此时直接向上合并即可:
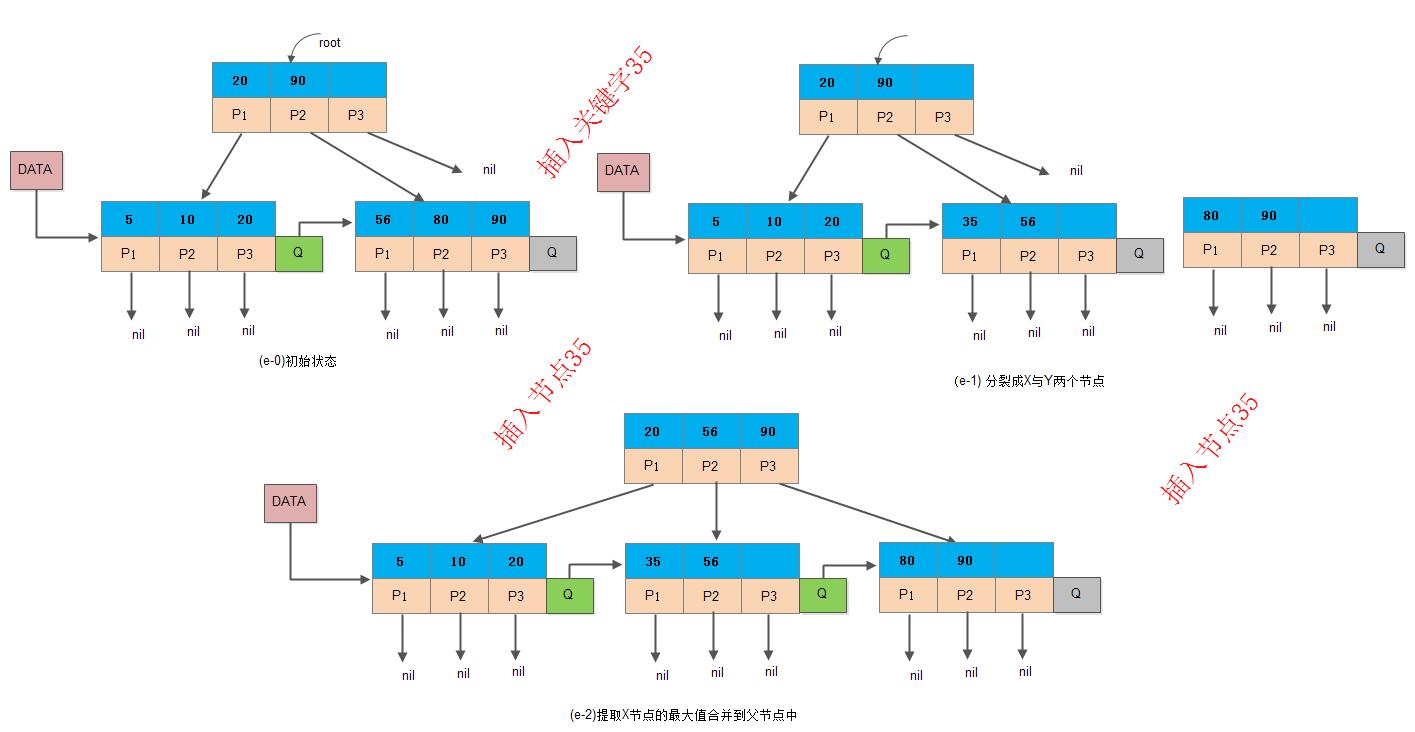
5) 当前节点是非根节点,且插入后节点关键字数目大于3
如下图所示,当前插入节点是非根节点,且插入关键字100后关键字数目大于3, 需要进行分裂:
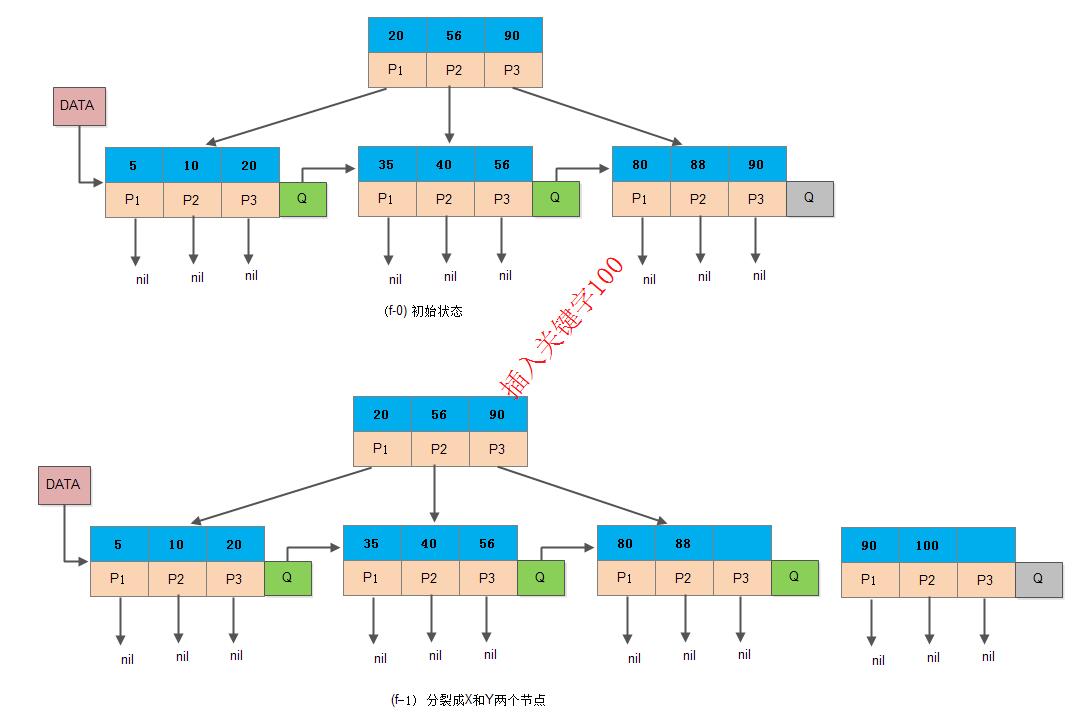
分裂后新插入关键字100是Y节点的新索引值,此时需要先从上至下用100替换原来老的索引值90:
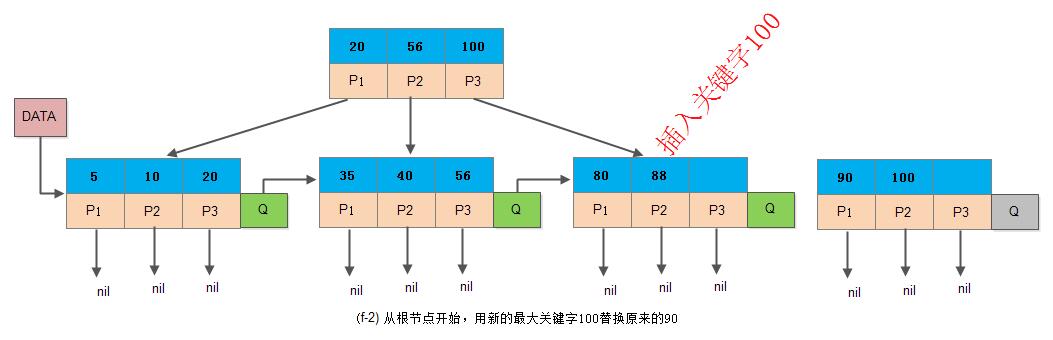
然后提取X节点的索引值, 与Y节点一起归并到上级节点中:
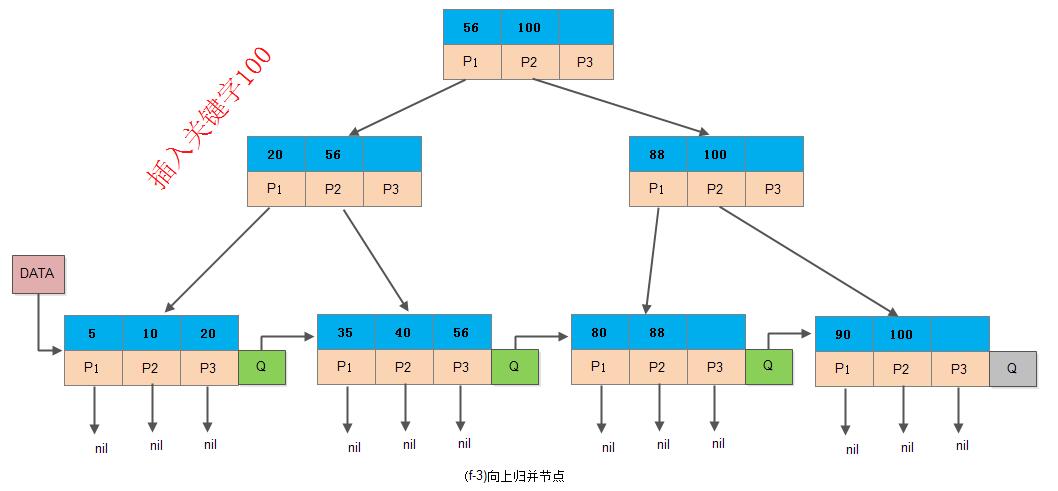
4. B+树的删除
B+树的删除也仅在叶子节点中进行,当叶子节点中的最大关键字被删除时,其在非终端节点中的值可以作为一个分界关键字存在。若因删除而使节点中关键字的个数少于⌈m/2⌉时,其和兄弟节点的合并过程亦和B-树类似。
5. 与B-树的比较
一棵m阶的B+树和m阶的B树的异同点在于:
-
所有的叶子节点中包含了全部关键字的信息,即指向含有这些关键字记录的指针,且叶子节点本身依关键字的大小
自小而大的顺序链接。(而B-树的叶子节点并没有包括全部需要查找的信息) -
所有的非终端节点可以看成是索引部分,节点中仅含有其子树根节点中最大(或最小)关键字。(而
B-树的非终节点也包含需要查找的有效信息)
6. B+树用途
B+树主要适用于索引操作。为什么说B+树比B-树更适合实际应用于操作系统的文件索引和数据库索引?
-
B+树的磁盘读写代价更低:B+树的内部节点并没有指向关键字具体信息的指针。因此其内部节点相对B-树更小。如果把所有同一内部节点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就越多。相对来说IO读写次数也就降低了。举个例子:假设磁盘中的一个盘块容纳16bytes,而一个关键字2bytes, 一个关键字具体信息指针2bytes。一棵9阶B-树(一个节点最多8个关键字)的内部节点需要2个盘块。而B+树内部节点只需要1个盘块。当需要把内部节点读入内存的时候,B-树就比B+树多一次盘块查找时间(在磁盘中就是盘片旋转时间) -
B+树的查询效率更加稳定: 由于非终节点并不是最终指向文件内容的节点,而只是叶子节点中关键字的索引。所以任何关键字的查找必须走一条从根节点到叶子节点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
7. Mysql中B+树的应用
其实B-树及B+树最需要关注的是它们的应用。B-树和B+树常被用于数据库中,作为Mysql数据库索引。索引(index)是帮助MySQL高效获取数据的数据结构。
为了查询更加高效,所以采用B+树作为数据库索引。在MySQL中,索引属于存储引擎级别的概念,不同存储引擎对索引的实现方式是不同的。我们接下来讨论两个引擎:MyISAM和InnoDB这两种引擎。
7.1 MyISAM
MyISAM中有两种索引,分别是主索引和辅助索引,在这里面的主索引使用具有唯一性的键值进行创建,而辅助索引中键值可以是相同的。MyISAM分别会存在一个索引文件和数据文件,它的主索引是非聚集索引。当我们查询的时候,我们找到叶子节点中保存的地址,然后通过地址我们找到对应的信息。
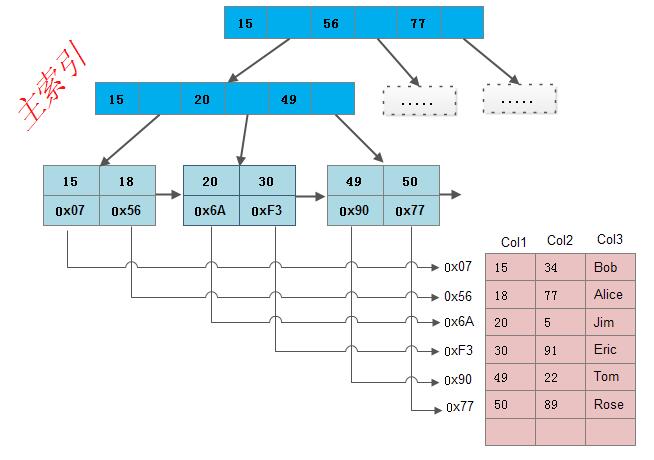
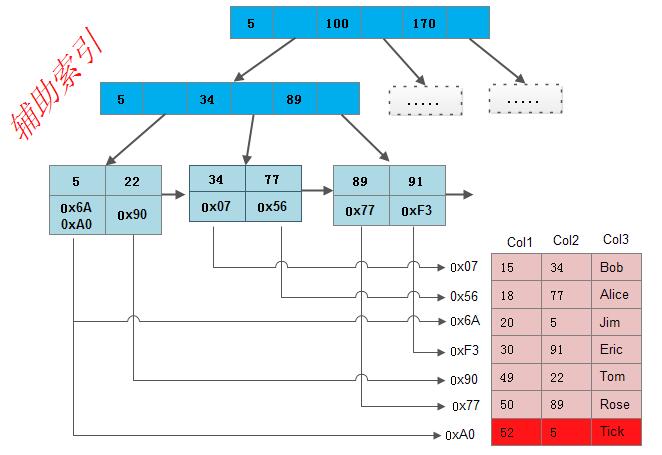
注: ISAM,即Indexed Sequential Access Method(索引顺序访问方法)
7.2 InnoDB
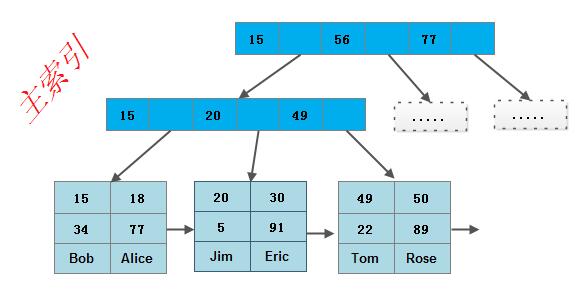
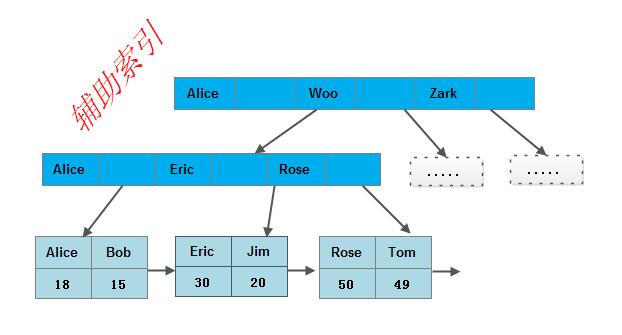
InnoDB索引和MyISAM的最大区别是它只有一个数据文件。在InnoDB存储引擎中,表数据文件本身就是按B+树组织的一个索引结构,这棵树的叶节点数据保存了完整的数据记录,所以我们把它的主索引叫做聚集索引。而它的辅助索引和MyISAM也会有所不同,它的辅助索引都是将主键作为数据域,所以这样当我们查找的时候通过辅助索引先找到主键,然后通过主索引找到对应的主键,从而得到相应的数据信息。
7.3 MyISAM与InnoDB比较
MyISAM与InnoDB都是Mysql的存储引擎。从历史上来说MyISAM历史更加久远,所以InnoDB性能也就更好了。在这我们需要考虑当我们修改数据库中的表的时候,数据库发生了变化,那么主键的地址也就发生了变化,这样你的MyISAM的主索引和辅助索引就需要进行重新建立索引。而InnoDB只需要改变主索引,因为它的辅助索引是存主键的。所以这样考虑InnoDB更加高效。
另外,我们也就很容易明白为什么不建议使用过长的字段作为主键,因为所有辅助索引都引用主索引,过长的主索引会令辅助索引变得过大。
7.4 MySQL采用B+树原因
MySQL等数据库普遍都采用B+树,而不是B-树。主要有如下原因:
1) B-树和B+树最重要的一个区别就是B+树只有叶子节点存放数据,其余节点用来索引。而B-树是每个索引节点都会有data域。这就决定了B+树更适合用来存储外部数据。也就是所谓的磁盘数据。
2) 从MySQL InnoDB的角度来看,B+树是用来充当索引的,一般来说索引非常大,尤其是关系型数据库这种数据量大的索引能达到亿级别,所以为了减少内存的占用,索引也会存储在磁盘上。
3) B+树的磁盘读写代价更低。B+树的内部节点并没有指向关键字具体信息的指针,因此其内部节点相对B-树更小。如果把所有同一内部节点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就越多。相对来说IO读写次数也就降低了。
4) B+树的查询效率更加稳定。由于非终节点并不是最终指向文件内容的节点,而只是叶子节点中关键字的索引。所以任何关键字的查找必须走一条从根节点到叶子节点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
5) B+树所有的Data域在叶子节点,一般来说都会进行一个优化,就是将所有的叶子节点用指针串起来。这样遍历叶子节点就能获得全部数据,这样就能进行区间访问了。
7.5 关于聚簇索引与非聚簇索引
在《数据库原理》里面,对聚簇索引的解释是: 聚簇索引的顺序就是数据的物理存储顺序; 而对非聚簇索引的解释是: 索引顺序与数据物理排列无关。正是因为如此,所以一个表最多只能有一个聚簇索引。直观上来说,聚簇索引的叶子节点就是数据节点; 而非聚簇索引的叶子节点仍然是索引节点,只不过是指向对应数据块的指针。
[参看]: